Recherche limitée à un seul syntagme
Recherche limitée à un seul syntagme dans 5 000 documents au maximum
à
Recherche du contexte
Notice de Gallicagram
- Gallicagram est un programme représentant graphiquement l’évolution au cours du temps de la fréquence d’apparition d’un ou plusieurs syntagmes dans les corpus numérisés de Gallica et de beaucoup d’autres bibliothèques.
- Développé par Benjamin Azoulay et Benoît de Courson, il est intégralement rédigé en langage R et présente une interface graphique interactive Shiny.
- Les données produites sont téléchargeables par l’utilisateur. Le code source de Gallicagram est libre d’accès et de droits.
- L’analyse de la structure des recherches dans le corpus de presse de Gallica peut être réalisée dans Gallicapresse.
Corpus
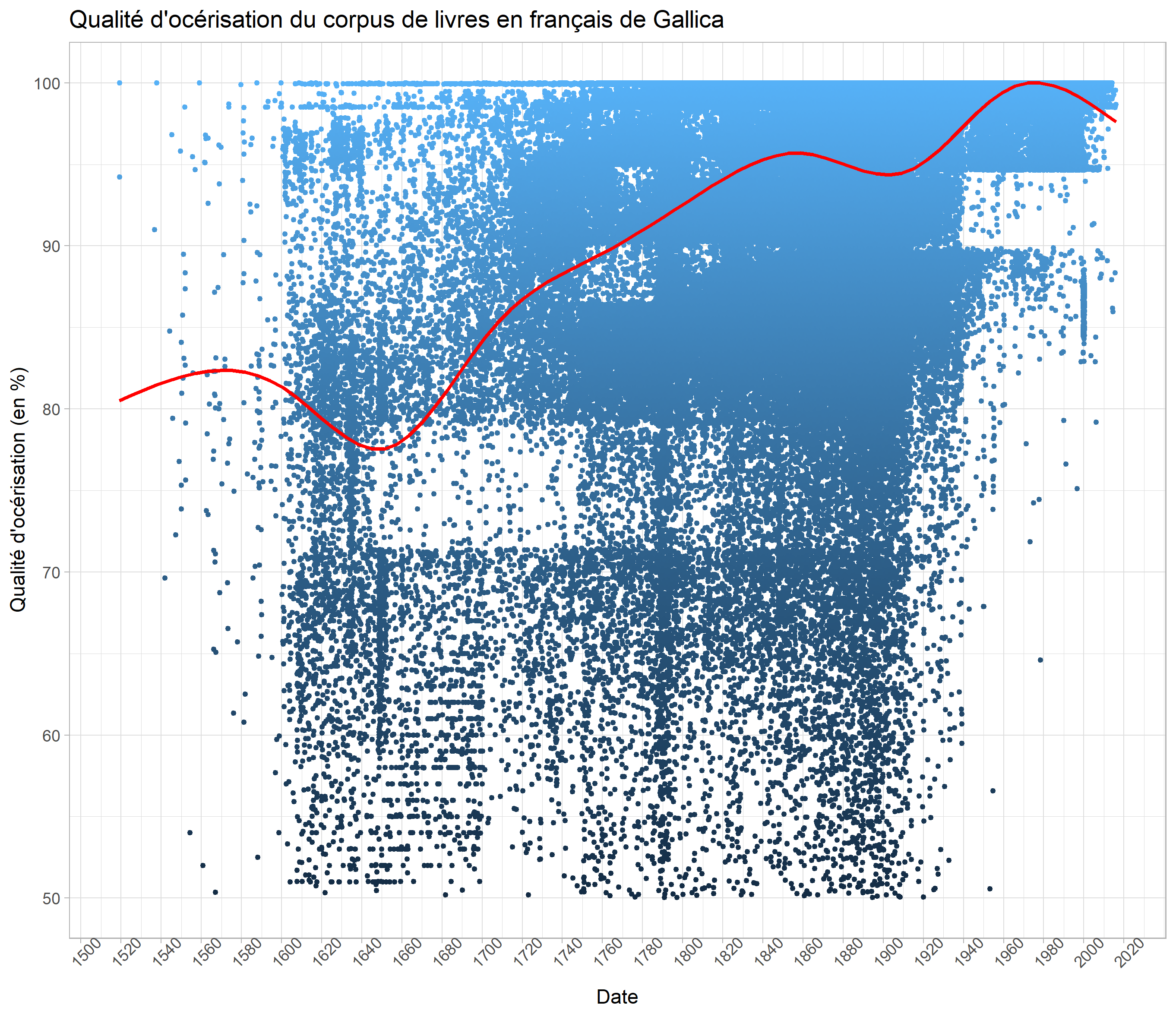
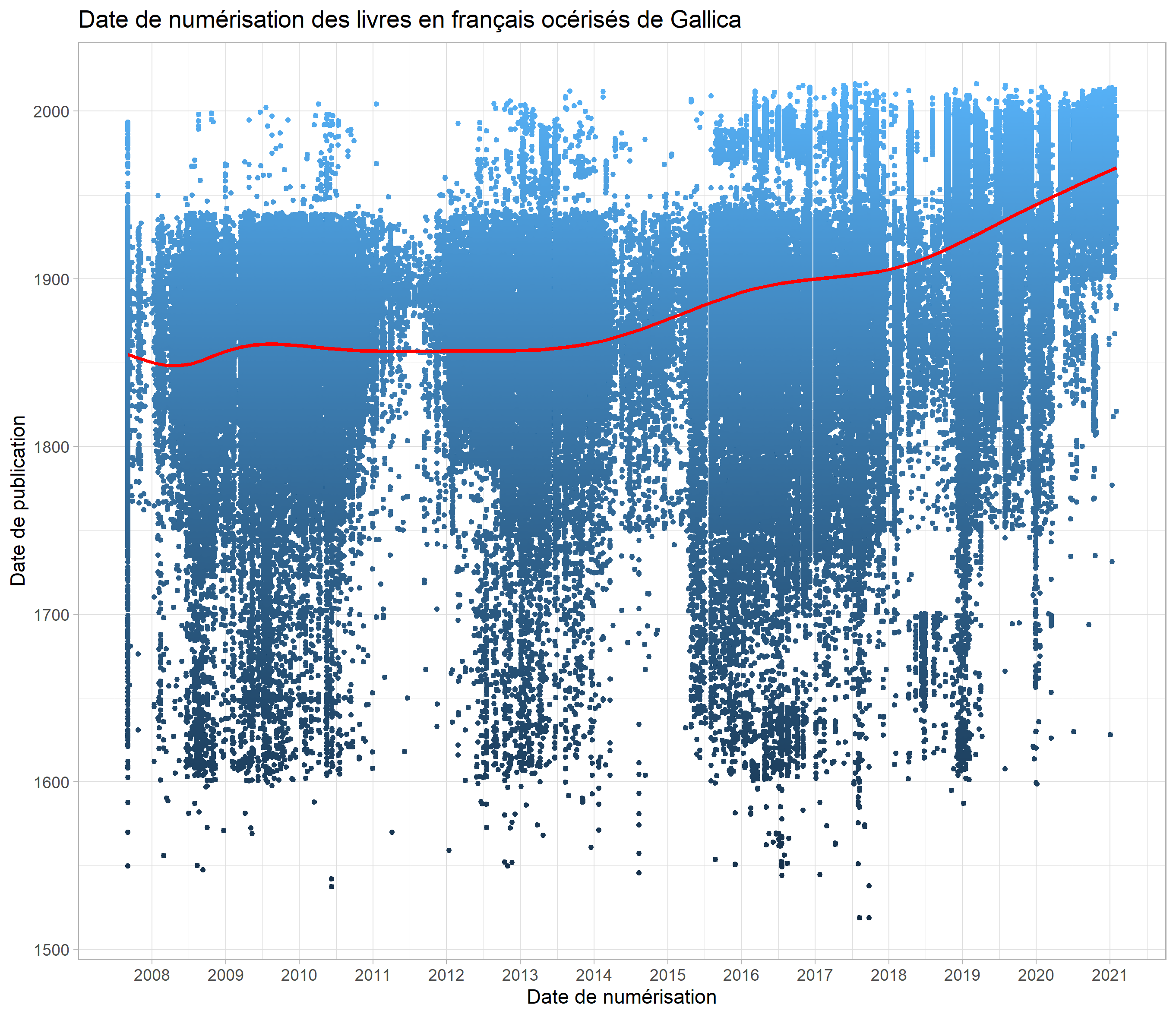
- Gallicagram a accès à de nombreuses bibliothèques. Quelle que soit la bibliothèque choisie, le corpus est circonscrit aux documents numérisés et océrisés et rédigés dans la langue choisie par l’utilisateur.
- Gallicagram permet aussi d’explorer des sous-corpus de Gallica totalement accessibles et bien documentés. De nombreux graphiques renseignant sur la structure des corpus de presse et de livres de Gallica sont présentés dans les onglets « Corpus de presse » et « Corpus de livres » de Gallicagram.
Options de recherche
- Gallicagram extrait des valeurs distinctes selon le mode de recherche sélectionné par l’utilisateur. En raison de l’architecture des moteurs de recherche propre à chaque bibliothèque, il est rare que plusieurs modes de recherche soient disponibles pour un même corpus. Les corpus de Gallica sont ceux qui présentent la plus grande diversité de modes de recherche.
- 4 modes de recherche sont proposés dans Gallicagram :
- la recherche par document (volume) compte, pour chaque sous-période, le nombre de documents du corpus présentant au moins une occurrence du syntagme recherché ;
- la recherche par page (page) compte, pour chaque sous-période, le nombre de pages du corpus présentant au moins une occurrence du syntagme recherché ;
- la recherche par article (article) compte, pour chaque sous-période, le nombre d’articles du corpus de presse présentant au moins une occurrence du syntagme recherché ;
- la recherche par n-gramme(match) compte, pour chaque sous-période, le nombre total d’occurrences du syntagme recherché dans le corpus.
- L’utilisateur peut choisir le corpus qu’il souhaite explorer.
- Il peut régler les bornes chronologiques de sa recherche.
- Pour certains corpus, il peut choisir la résolution (mensuelle ou annuelle) avec laquelle les résultats seront affichés.
- Pour chaque mode de recherche et chaque corpus, Gallicagram extrait aussi le volume de la base de données correspondante (nombre total de documents, de pages, d’articles, ou de n-grammes pour chaque sous-période).
Syntaxe de recherche
- L’utilisateur peut chercher un syntagme unique (ex. Clemenceau).
- Il peut aussi comparer les évolutions respectives de deux syntagmes concurrents en les séparant par une esperluette “&” (ex. Georges Clemenceau&Aristide Briand).
- Il peut effectuer une recherche conditionnelle de forme OU en utilisant le signe “+” (ex. juif+juive). Il s’agit d’un “ou” inclusif qui renverra tous les numéros contenant les termes séparés par un “+”. La recherche dénombre des syntagmes exacts et isolés. Ainsi, entrer le mot “juif” ne permettra pas d’obtenir les résultats correspondant à son pluriel : “juifs”. La recherche conditionnelle OU avec “+” permet d’intégrer ces résultats.
- Dans le mode de recherche “Par document” (et non “Par N-gramme”, comme par défaut), il peut chercher des cooccurrences dans les corpus de Gallica à l’aide de l’opérateur “*” (ex. universel*nation). Une case apparait alors à côté du champ de la requête pour définir la distance maximale entre les termes recherchés (en nombre de mots).
- Ces trois options de recherche sont cumulables (ex. juif+juive+judéo&calviniste+huguenot+parpaillot ; ex. universel*nation+universel*patrie&étranger*ennemi). “&” est prioritaire sur “*” qui est prioritaire sur “+”. Ainsi a*b+c*d&e = [(a*b)+(c*d)]&e
- La recherche n’est pas sensible à la casse (case insensitive).
Options de visualisation
- L’utilisateur peut :
- isoler certaines recherches dans le visualiseur en cliquant sur la légende des courbes qu’il souhaite faire disparaître ;
- effectuer des zooms sur le graphique et afficher la valeur précise de chaque point de la courbe en y positionnant la souris ;
- afficher la distribution chronologique des documents composant la base de données sur la période qu’il a choisie ;
- comparer toutes les recherches effectuées au cours de sa session à l’intérieur d’un seul graphique ;
- accéder à la recherche correspondante (syntagme, corpus, sous-période) sur le site de la bibliothèque explorée afin d’accéder au corpus sous-jacent à la recherche ;
- normaliser les valeurs ;
- lisser les courbes affichées (type loess) ;
- comparer l’évolution de deux syntagmes par soustraction ;
- observer les corrélations entre les syntagmes recherchés ;
- observer les corrélations pour un même terme entre les différents modes de recherche ;
- télécharger les graphes et les données du visualiseur ainsi que les données de la totalité de la session.
8 Types de visualisation différents
- Courbes : courbes d’évolution entourées de leur marge d’erreur calculée en fonction du volume de la base et de la fréquence d’occurrence du terme recherché. Présentation par défaut de Gallicagram.
- Sommes : graphique en barres horizontales figurant la somme des occurrences des différents mots sur l’ensemble de la période étudiée. Tri par ordre décroissant d’occurrences.
- Histogrammes : graphique en barres verticales figurant le nombre d’occurrences de chacun des termes recherchés au cours du temps.
- Bulles : graphique en bulles figurant la fréquence d’occurrence de chacun des termes recherchés au cours du temps. Tri des termes par ordre décroissant en regard de la somme des occurrences sur l’ensemble de la période. La fonction rescale permet de faire apparaître les termes les moins fréquents.
- Aires : graphique en aires figurant la fréquence d’occurrence de chacun des termes recherchés au cours du temps. Tri des termes par ordre décroissant en regard de la somme des occurrences sur l’ensemble de la période.
- AFC : graphique figurant le résultat de l’analyse factorielle des correspondances pour les termes recherchés sur la période étudiée. Le graphique représente à la fois les termes et les dates selon les deux axes principaux calculés par l’AFC.
- Nuage de mots : graphique en nuage de mots. Chaque bulle représente un terme de recherche sur l’ensemble de la période analysée. Son diamètre est proportionnel à la fréquence d’apparition du terme sur l’ensemble de la période.
- Polaires : graphique en coordonnées polaires. Ce mode permet d’étudier la saisonnalité des termes recherchés. Ici la fonction “loess” calcule la différence par rapport à la moyenne mobile sur douze mois. Une option avancée permet d’étudier les moyennes mensuelles sur l’ensemble de la période (un cercle par mot).
Traitements
- Le traitement des données extraites consiste au calcul pour chaque sous-séquence temporelle de la fréquence d’apparition du terme défini par l’utilisateur. Cette fréquence est le rapport des deux variables extraites (le nombre de résultats et le volume de la base) soit pour une sous-séquence temporelle :
$$ ratio_i=\frac{count_i}{base_i} =\frac{x_i}{N_i} $$
- Le graphique présente cette fréquence en ordonnées et le temps en abscisses selon l’échelle sélectionnée. La courbe qu’il affiche relie les points calculés par l’ordinateur.
Conception et précautions d’usage
- Toutes les informations nécessaires à la bonne utilisation de Gallicagram sont indiquées dans l’article de recherche associé à ce logiciel.
Corpus disponibles / langue / mode de recherche
Tutoriel et Séminaire de présentation
Présentation de Gallicagram
Bibliographie
Articles décrivant Gallicagram
- Benoît de Courson, Benjamin Azoulay, Clara de Courson, Laurent Vanni et Étienne Brunet, « Gallicagram : les archives de presse sous les rotatives de la statistique textuelle », Corpus, 2023, https://doi.org/10.4000/corpus.7944
- Benjamin Azoulay et Benoît de Courson, « Gallicagram, un outil de lexicométrie pour la recherche », 2021, https://doi.org/10.31235/osf.io/84bf3
- Benjamin Azoulay, Benoît de Courson et Will Gleason, « Compter les mots pour remonter le temps : Gallicagram et Gallicagrapher, deux outils d’exploration des archives numérisées de la BnF », Culture et Recherche, n°144, printemps-été 2023, p. 82, https://u-picardie.hal.science/public/Culture_et_Recherche_144_La_science_ouverte.pdf
- Benoît de Courson, « LRFAF : une exploration numérique du rap français depuis les années 1990 », 2024, https://doi.org/10.31235/osf.io/d96tr
- « Actualités - Gallicagram : un outil de lexicométrie pour la recherche », novembre 2021, https://odhn.ens.psl.eu/newsroom/gallicagram-un-outil-de-lexicometrie-pour-la-recherche
- « Utiliser les API de Gallica : L’exemple de Gallicagram », https://api.bnf.fr/fr/gallicagram-un-outil-de-lexicographie
- Anne Bugner, « Présentation critique d’un outil numérique à destination de la recherche en SHS : Gallicagram », Mémoire de master, 2022, Ecole nationale des chartes - PSL
Travaux utilisant Gallicagram
- Olivier Ritz, « Gallicagram: un outil d’exploration pour l’histoire littéraire de la Révolution », Littérature et Révolution, 7 novembre 2022, https://litrev.hypotheses.org/2449
- Alexandre Grit, « Gallicagram : un outil pour comprendre les enjeux d’opinion à propos de la soutenabilité budgétaire ? », Mémoire de master, Ecole normale supérieure Paris-Saclay, 2022, https://hal.archives-ouvertes.fr/hal-03845936
- Benjamin Azoulay, Abel Bonnard, Plume de la Collaboration, Perrin, Paris, 2023, 384p., https://www.lisez.com/livre-grand-format/abel-bonnard/9782262095376
- Elise Meyer, La mémoire de la bataille de Valmy, de 1792 à nos jours, thèse de doctorat dirigée par Philippe Buton, Université de Reims Champagne-Ardenne, 2022, https://www.theses.fr/s147190
- Pearl Pandya, Armin Pournaki, Jean-Philippe Cointet, “What’s the news on Muslims in India?”, juillet 2023, https://pearlpandya.com/public/np_poster_web.pdf
- Nicolas Perreaux, « L’avenir d’un féodalisme incertain ? Ruptures, paradigmes scientifiques et enjeux théoriques », L’atelier du Centre de Recherches Historiques, 2023, n°27, https://doi.org/10.4000/acrh.28121
- François Jacquesson, « L’auto et le vélo », Caramel, Sciences du langage et monde contemporain, 7 décembre 2022, https://caramel.hypotheses.org/24021
- François Jacquesson, « Le bel aujourd’hui », Caramel, Sciences du langage et monde contemporain, 30 décembre 2022, https://caramel.hypotheses.org/25103
- François Jacquesson, « Ciels ! », Caramel, Sciences du langage et monde contemporain, 13 juin 2023, https://caramel.hypotheses.org/31634
- François Jacquesson, « Connaissez-vous le code ? », Caramel, Sciences du langage et monde contemporain, 18 juin 2023, https://caramel.hypotheses.org/31984
- François Jacquesson, « Euthanasie », Caramel, Sciences du langage et monde contemporain, 4 juillet 2023, https://caramel.hypotheses.org/32701
- François Jacquesson, « Place de l’Utopie, allez tout droit ! », Caramel, Sciences du langage et monde contemporain, 15 juillet 2023, https://caramel.hypotheses.org/33066
- François Jacquesson, « L’espion pris dans la guerre », Caramel, Sciences du langage et monde contemporain, 10 août 2023, https://caramel.hypotheses.org/34168
- François Jacquesson, « Le dernier homme », Caramel, Sciences du langage et monde contemporain, 21 août 2023, https://caramel.hypotheses.org/34526
- François Jacquesson, « Les mots manquent », Caramel, Sciences du langage et monde contemporain, 5 décembre 2023, https://caramel.hypotheses.org/39263
- François Jacquesson, « Le songe, le rêve, et Prospero », Caramel, Sciences du langage et monde contemporain, 30 novembre 2023, https://caramel.hypotheses.org/39086
- François Jacquesson, « Le monde, le vrai, et l’intelligence artificielle », Caramel, Sciences du langage et monde contemporain, 18 octobre 2023, https://caramel.hypotheses.org/37169
- François Jacquesson, « L’air du temps », Caramel, Sciences du langage et monde contemporain, 14 novembre 2023, https://caramel.hypotheses.org/38342
- François Jacquesson, « L’actu a disparu », Caramel, Sciences du langage et monde contemporain, 19 novembre 2023, https://caramel.hypotheses.org/38561
- François Jacquesson, « Le songe, le rêve, et Prospero », Caramel, Sciences du langage et monde contemporain, 30 novembre 2023, https://caramel.hypotheses.org/39086
- François Jacquesson, « Les mots manquent », Caramel, Sciences du langage et monde contemporain, 5 décembre 2023, https://caramel.hypotheses.org/39263
- François Jacquesson, « Le fantôme d’Éléonore », Caramel, Sciences du langage et monde contemporain, 20 mars 2024, https://caramel.hypotheses.org/43727
- François Jacquesson, « L’anglais et “nous” », Caramel, Sciences du langage et monde contemporain, 11 avril 2024, https://caramel.hypotheses.org/44671
- François Jacquesson, « Alibi », Caramel, Sciences du langage et monde contemporain, 27 avril 2024, https://caramel.hypotheses.org/45300
- François Jacquesson, « Pauvre, politique, prolétaire, élections », Caramel, Sciences du langage et monde contemporain, 29 juin 2024, https://caramel.hypotheses.org/48054
- François Jacquesson, « Jaune, Rouge : couleur de peau ? », Caramel, Sciences du langage et monde contemporain, 6 juillet 2024, https://caramel.hypotheses.org/48154
- François Jacquesson, « Glamour : cœur solitaire en société », Caramel, Sciences du langage et monde contemporain, 24 juillet 2024, https://caramel.hypotheses.org/49035
- François Jacquesson, « Ocelle », Caramel, Sciences du langage et monde contemporain, 22 août 2024, https://caramel.hypotheses.org/49955
- Madeleine Leroy. « „Bäder bauen heißt Spitäler sparen“. Piscines et bains-douches publics de « Vienne la rouge » (1919-1934) comme éléments d’une politique urbaine d’hygiène sociale », 2021, https://dumas.ccsd.cnrs.fr/dumas-03416702
- Erwan Le Gall, « A propos de l’antimilitarisme des Sârs et de la rougeole politique (1913) », Ar Brezel, 5 janvier 2022, https://arbrezel.hypotheses.org/4804
- Erwan Le Gall, « Février 1918 : l’estuaire de la Loire au bord de la Révolution ? », Ar Brezel, 2 février 2022, https://arbrezel.hypotheses.org/4963
- Erwan Le Gall, « La Grande Guerre comme rupture ? A propos de César Chabrun », Ar Brezel, 18 mai 2022, https://arbrezel.hypotheses.org/6355
- Erwan Le Gall, « À propos de la peur du maquis », Ar Brezel, 12 février 2023, https://arbrezel.hypotheses.org/8879
- Olivier Jacquot, « Le « novohispanisme », champ impensé des sciences sociales», Amoxcalli, 26 mai 2022, https://amoxcalli.hypotheses.org/42495
- Michel Bollard, « Témoignage : Gallicagram, la lexicographie accessible », Coll’Explorar, 2 septembre 2024, https://doi.org/10.58079/127rv
- Feargal McKay, « Mythologies: Alphonse Steinès and the Invention of the Pyrénées », Podium Cafe, 20 mars 2022, https://www.podiumcafe.com/book-corner/2022/3/20/22925846/alphonse-steines-tourmalet-aubisque-tour-de-france
- Jana Altmanova, Emmanuel Cartier, Jimmy Luzzi, Sarah Pinto et Sergio Piscopo, « Innovations lexicales dans le domaine de l’environnement et de la biodiversité : le cas de bio en français et en italien », Neologica, n° 16, 2022, Néologie et environnement, p. 85-110, https://dx.doi.org/10.48611/isbn.978-2-406-13219-6.p.0085
- K. Bender, « A voyage to Cythera (3): among publishers and their fake imprints », 23 octobre 2022, https://kbender.blogspot.com/2022/10/111-voyage-to-cythera-3-among.html?view=classic
- Benoît Roux, « FAIR Way : approches éthique et épistémologique », Eveille, 16 mai 2022, https://eveille.hypotheses.org/2565
- Noé Leroy, « Étude sémantico-historique du terme seruus entre le 9e et le 13e siècle : essai de diplomatique numérique », Université catholique de Louvain, 2022, https://dial.uclouvain.be/memoire/ucl/en/object/thesis%3A37571
- Franck Antoni, « De ces exemples tout à fait banaux… », 25 novembre 2022, https://franckantoni.com/pluriel-banals-ou-banaux/
- Alban Lannéhoa, « Une histoire de la frégate », 28 mars 2023, https://tribord-amure.fr/2023/03/28/une-histoire-de-la-fregate/?fbclid=IwAR05B8cwGaDb7bsXB9-n6zAlBLYjsvPj3dNrkH27Dm3puJKLfIU02967oHg
- Edmée Garcia-Mariller, « Dire son “Mood” : une nouvelle forme de la narration de soi. Étude linguistique et sémiologique de la sous-culture du “Mood” », Mémoire de Master, 2022, SU CELSA - Sorbonne Université, https://dumas.ccsd.cnrs.fr/dumas-04033748v1
- Gaëtan Bonnot, « Des traces aux échos d’une révolte : études sur la Jacquerie de 1358 », Thèse de doctorat, 2022, Université Paris I - Panthéon Sorbonne, Ecole doctorale d’histoire, LAMOP - Laboratoire de Médiévistique Occidentale de Paris, https://hal.science/tel-04043231v1
- Arnaud Laborderie, Florence Tfibel, « Ouvrir les données de la Bibliothèque nationale de France pour la recherche », 2023, https://hal-bnf.archives-ouvertes.fr/hal-04074665
- Benjamin Bober, « Les haches de pierre en contexte gallo-romain - Au delà de la pierre de foudre », Septembre 2023, https://www.researchgate.net/publication/374199024_Les_haches_de_pierre_en_contexte_gallo-romain_-_Au_dela_de_la_pierre_de_foudre
- Claire-Lise Gaillard, « Feuilleter la presse ancienne par gigaoctets », Studies in Digital History and Hermeneutics, 2022, p. 113, https://library.oapen.org/bitstream/handle/20.500.12657/61093/9783110729214.pdf?sequence=1#page=122
- « E2533e – Release of the NDL Ngram Viewer: A Service to Visualize Full-Text Data», Current Awareness Portal, n°442, 1er septembre 2022, https://current.ndl.go.jp/en/e2533_en
- Nicolas Ragonneau, « Pasticher sans peine », Le Coin des Assimilistes, 26 juillet 2023, https://blog.assimil.com/pasticher-sans-peine/
- Jules Verne, Famille-Sans-Nom, Introduction - « Mon pays de prédilection »: le Canada de Jules Verne, 2024, https://classiques-garnier.com/famille-sans-nom-le-canada-de-jules-verne-ii-introduction.html
- Nicolas Chachereau et Cédric Humair, « Méthodes informatiques et quantitatives en histoire du tourisme: apports et limites », Mondes du Tourisme, 2023, no 24, https://journals.openedition.org/tourisme/6201
- Béatrice Joyeux-Prunel, Marie Barras et Nicola Carboni, « Une Europe par les arts ? Les périodiques illustrés au-delà du Musée imaginaire », Artl@s Bulletin, 2023, vol. 12, no 1, p. 12, https://docs.lib.purdue.edu/artlas/vol12/iss1/12/
- Laurent Vanni, « Hyperbase Web.(Hyper) », Bases Corpus, Langage. Corpus, 2023, no 25, https://journals.openedition.org/corpus/8770
- Romain Jalabert, « Le “grand tapage de journaux” autour de Chateaubriand en 1831 », La Revue des lettres modernes, 2023, vol. 2023, p. 155-170, https://classiques-garnier.com/sociabilites-litteraires-2023-7-le-grand-tapage-de-journaux-autour-de-chateaubriand-en-1831.html
- David Aubin « Popularizing precision: cultures of exactness at the Paris observatory, 1667–1742 », Annals of Science, 2024, 81:1-2, 139-159, https://doi.org/10.1080/00033790.2023.2282783
- Corentin Marion, « Nationalism and Internationalism Intertwined. A European History of Concepts Beyond the Nation State, New York, Oxford (Berghahn) 2022 », Francia-Recensio, 2023, https://journals.ub.uni-heidelberg.de/index.php/frrec/article/view/101586
- Marc Nikitin, « Le mot comptabilité s’est répandu à la fin du XVIIIe siècle pour désigner une technique de gouvernement», Comptabilité(s), revue d’histoire des comptabilités, 2023, n°15, https://journals.openedition.org/comptabilites/6513
- Marie Lucie Bougon, SÉMINAIRE LPCM – SÉANCE 3, JEUDI 11 JANVIER 2023, 17H-19H : “PROSPECTIVE ET SCIENCE-FICTION : ENJEUX MÉTHODOLOGIQUES ”, https://lpcm.hypotheses.org/31380
- Podcast Paroles d’histoire, épisode 339, https://parolesdhistoire.fr/index.php/2024/04/07/330-quand-le-monde-devint-mondial-avec-vincent-capdepuy/
- Simon Apartis, « De quoi l’impact est-il le nom ? », Works of the Open Knowledge Cluster of the CNRS Center for Internet and Society, Paris, 17 juin 2024, https://ok.hypotheses.org/4733
- Elie Allouche « Transformation numérique de l’éducation, approche systémique et recherche appliquée », Médiations & médiatisations no. 17, p. 75–107, avril 2024, https://doi.org/10.52358/mm.vi17.392
- Gerda Hassler. Le contexte en question, p.11, ISTE Group, 2024, https://books.google.fr/books?hl=fr&lr=&id=t3oUEQAAQBAJ
- Géraldine Farges, et Szerdahelyi Loïc, « Renforcer, par la formation, l’attractivité du métier d’enseignant », Constructif, vol. 68, no. 2, 2024, pp. 64-66, https://doi.org/10.3917/const.068.0064
- Christophe Gérard, « Approche discursive de la néologie-Proposition d’un cadre conceptuel », Neologica, 2024, vol. 2024, no 18, p. 17-75, https://classiques-garnier.com/neologica-2024-n-18-pour-une-approche-discursive-de-la-neologie-approche-discursive-de-la-neologie.html
- Gildas Grimault, « « Brittophone » : aux origines d’un conflit terminologique », Cahiers internationaux de sociolinguistique, vol. 24, no. 1, 2024, pp. 71-89, https://doi.org/10.3917/cisl.2401.0071
- Daniel Torres Salinas, et al. « Culturomics con Google Ngram Viewer & Wikipedia », 2024, http://dx.doi.org/10.5281/zenodo.10842119
Conférences de présentation de Gallicagram
- Séminaire Digital Humanities / Artificial Intelligence (DHAI) - Ecole normale supérieure, 11 mai 2021 : http://savoirs.ens.fr/expose.php?id=3989
- Séminaire Numapresse, 14 février 2022 : http://www.numapresse.org/2022/01/24/le-seminaire-numapresse-reprend-rendez-vous-le-14-fevrier-a-14h/
- Formation à Gallicagram au DataLab - Bibliothèque nationale de France, 16 mai 2022
- Congrès Média 19, 30 mai 2022 : https://bnf.hypotheses.org/12916
- Séminaire Quantitativisme réflexif, 28 octobre 2022 : https://www.idhes.cnrs.fr/seminaire-quantitativisme-reflexif-2022-23/
- Séminaire Méthodologie de la recherche, Master Lettres - Sorbonne Université, 21 octobre 2022
- Séminaire du laboratoire Econophysix - Ecole Polytechnique, 27 octobre 2022
- Séminaire Evolution, Cognition and Culture Conference - ENS Ulm, 28 novembre 2022
- Présentation de l’outil de lexicométrie Gallicagram, ADEMEC - Ecole des Chartes, 23 janvier 2023 : https://www.eventbrite.fr/e/billets-atelier-n4-presentation-de-loutil-de-lexicometrie-gallicagram-505923700407
- Séminaire MédiaLab - SciencesPo, 28 février 2023
- Séminaire IMAREV, Gallicagram : impressions de la Révolution - Université Paris Cité, 24 mars 2023 : https://imarev.hypotheses.org/366
- Séminaire ISOCO Indices d’opinion sociaux économiques - Université Paris Nanterre, 6 juillet 2023 : https://calenda.org/1052826
- Laetitia Gonon : « Frantext et gallicagram », Journée d’accueil et de formation des doctorants du CÉRÉDI - Université de Rouen, 21 novembre 2023 : https://ceredi.hypotheses.org/8056
- Approche computationnelle de gros corpus de textes : Gallicagram, Pacte, Laboratoire de sciences sociales, Sciences Po Grenoble, 19 janvier 2024 : https://www.pacte-grenoble.fr/fr/actualites/approche-computationnelle-gros-corpus-textes-gallicagram
- Présentation de Gallicagram et TD au lycée Corot de Savigny, 23 mai 2024 : https://x.com/gallicagram/status/1793618881833283925
- Les lundis de l’INED, Campus Condorcet, 27 mai 2024 : https://www.ined.fr/fr/actualites/rencontres-scientifiques/les-lundis/gallicagram-un-outil-de-lexicometrie-pour-explorer-de-grands-corpus-diachroniques/
- Séminaire Capitalisme littoral et environnement, Institut LUDI, La Rochelle Université, 21 juin 2024, https://x.com/pierre_labardin/status/1750254315598455145/photo/1
Projets fondés sur Gallicagram
- Pyllicagram (API Python) par Benoît de Courson : https://github.com/regicid/pyllicagram
- Ruby Gem Gallicagram par Nicolas Le Roux : https://github.com/nicolrx/gallicagram
- Rallicagram (package R) par Vincent Bagilet : https://github.com/vincentbagilet/rallicagram
Bases de données pour l’entrainement de LLM
- HuggingFace, French Public Domain Newspapers : https://huggingface.co/datasets/PleIAs/French-PD-Newspapers
- HuggingFace, French Public Domain Book : https://huggingface.co/datasets/PleIAs/French-PD-Books
Projets utilisant Gallicagram
- Gallibase par Etienne Brunet et Laurent Vanni : http://ancilla.unice.fr/pages/bases/
- Gallica Grapher par Will Gleason : https://www.gallicagrapher.com/
- La Langue Française par Nicolas Le Roux : https://www.lalanguefrancaise.com/dictionnaire
- Aide à la recherche sur Gallica par Thomas Fressin (à venir)
- CNRTL, Lexicographie : https://www.cnrtl.fr/definition/ (à venir ; version béta)
Sites référençant Gallicagram comme outil
- https://www.wikidata.org/wiki/Q115121837
- http://www.bis-sorbonne.fr/sid/spip.php?article898
- https://marketplace.sshopencloud.eu/tool-or-service/bSv19B
- https://bu.univ-lyon2.fr/fle-sc-du-langage → ressources complémentaires
- https://numrha.hypotheses.org/2840
- https://numrha.hypotheses.org/4886
- https://www.fabula.org/actualites/111893/gallicagram.html
- https://lasciem.hypotheses.org/
- https://current.ndl.go.jp/en/e2533_en
- http://blog.ac-versailles.fr/starter/index.php/post/24/02/2022/GALLICAGRAM
- https://www.bases-netsources.com/component/flexicontent/category/conseil-semaine
- https://injs-bordeaux.org/blog/lexicometrie/
- https://eduscol.education.fr/3915/veille-education-numerique-2023-2024#VEN21092023
- https://pedagogie.ac-strasbourg.fr/lettres/enseigner-les-lettres-avec-le-numerique/outils-et-tutoriels/deux-outils-lexicometriques-pour-letude-de-mes-forets/